강화학습에 관심만 많던 차에 Andrej Karpathy가 훌륭한 튜토리알을 썼네요. 꼼꼼히 읽어볼 겸 번역합니다. 원문은
강화 학습에 대해 이야기할 내용이 많이 있다. 우선, 개인적으로 현재 인공지능 발전을 위해 해결해야할 문제를 아래 네 가지 정도로 보고있다.
컴퓨터 비전분야와 마찬가지로, 강화학습 역시 엄청나게 새로운 아이디어가 나타나서 이렇게 뜨고 있는것이 아니다. 2012년에 등장해 컨브넷의 시대를 연 알렉스넷은 대략 90년대의 컨브넷의 규모를 키운 버전이다. 마찬가지로 2013년에 소개된, 아타리 게임을 학습하는 Deep Q Learning은 함수 근사 (function approximator)로 컨브넷을 사용한 것을 제외하면 매우 일반적인 알고리즘이다 (함수 근사를 이용한 Q 학습은 1998의 Sutton 책에 소개된 내용이다). 알파고는 정책 그라디언트 (policy gradient)와 몬테-카를로 트리 탐색 (MCTS, Monte Carlo Tree Search)를 사용했는데 이 역시 널리 알려진 방법이다. 물론 이런 기본적인 방식이 이론상이 아니라 실제로 실험에서 잘 작동하게 하려면 각종 복잡한 기술을 동원해야한다. 하지만, 최근에 소개된 각종 연구의 일등공신은 알고리즘이 아니라 연산/데이터/환경이다.
퐁은 간단한 강화 학습용 예제로 아주 적절한 게임이다. 아타리2600버전을 보면 위/아래 화살표로 막대기를 조절해 공을 받아낸다. 만일 공을 받아치지 못하면 패배한다는 규칙이다. 데이터 관점에서 보면 이렇다. 각 화면은 210x160 픽셀이고 RGB채널을 고려하면 210x160x3바이트의 데이터가 된다. 연속된 화면을 받게 되므로 실제 데이터는 210x160x3크기의 성분으로 이루어진 어레이가 된다. 이 데이터를 받고, 막대기를 위로 올릴지 혹은 아래로 내릴지를 판단하면 된다. 이렇게 내린 모든 판단은 나중에 피드백을 받게 된다. 만일 상대가 공을 받는데 실패했다면 +1의 보상을, 내가 공을 못받았다면 -1을, 둘 다 아니면 0의 보상을 받는다. 당연히 +1의 보상을 받것이 우리의 목표다.
중요한건, 실제로 퐁을 어떻게 플레이하느냐가 문제가 아니라는 것이다. 복잡한 데이터가 들어오고, 우리가 어떤 판단을 내려야 보상이 극대화가 되는지를 자동으로 학습하도록 한다는 그 설정이 중요하다. 퐁은 그냥 예제로 선정된 게임일 뿐이다.
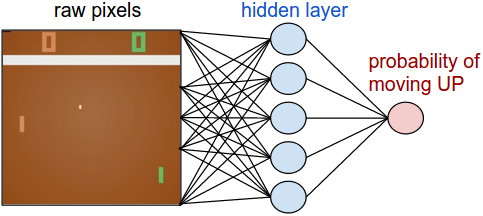
우선 정책망을 우리의 선수(player) 혹은 요원 (agent)라고 정의하자. 정책망은 현재 게임의 상태가 어떤지를 입력으로 받고 이를 토대로 우리가 어떤 행동을 취해야하는지 (UP or DOWN; 막대기를 위로 올릴지 아래로 내릴지)를 판단한다. 데이터(화면)과 레이블(행동) 사이를 인공 신경망으로 이어주자. 여기에서는 층이 2개인 인공 신경망을 사용할 것이다. 여기에서 입력은 100,800 (210 * 160 * 3)개의 노드가 되고 최종적으로 UP이 될 확률이 출력이 될 것이다. 이 구성은 흔하게 쓰이는 Stochastic 정책이다. (어떤 선택을 내릴지의 확률을 구하는 경우 여기에 해당한다.) 학습 과정에서 우리는 이 확률 분포를 토대로 어떤 행동을 취할 것인지를 샘플링을 한다. 예를 들어 70%의 확률로 UP인 상황이라면 p(UP):p(DOWN) = 7:3인 동전을 튀겨서 나온 결과를 사용한다. 이렇게 하는 이유는 뒤에서 설명하겠다.
이 과정을 파이썬 코드로 쓰면 아래와 같다.
h = np.dot(W1, x) # compute hidden layer neuron activations
h[h<0] = 0 # ReLU nonlinearity: threshold at zero
logp = np.dot(W2, h) # compute log probability of going up
p = 1.0 / (1.0 + np.exp(-logp)) # sigmoid function (gives probability of going up)
W1, W2는 임의의 값으로 초기화된다. Bias는 생략하자. 마지막 줄을 보면 sigmoid함수를 사용해서 결과 값이 [0, 1] 사이의 확률이 되도록 하는 것을 알 수 있다. 정리하면, 인공 신경망이 화면을 보고 게임 상황을 이해한 뒤 UP/DOWN중 무엇을 해야 하는지를 결정해주게 될 것이다. 학습 되기 전이라면 임의로 설정된 W1, W2가 어떤 판단이든 내릴 것이다. 자, 이제 학습을 통해 W1, W2가 의미있는 값이 되도록 - 즉 퐁을 플레이할 수 있도록 만들어주자!
팁: 전처리를 해야한다. 원래대로라면 적어도 2개 이상의 프레임 정보를 받아서 공의 움직임을 파악하게 해야한다. 여기에서는 연산량을 더 줄이기 위해 전 프레임과 다음 프레임의 차이를 입력으로 넣어주자.
가능한가?
우선 강화 학습이 얼마나 까다로운 문제인지를 파악해보자. 입력 값으로 100,800개의 값을 받고 그 결과로 UP/DOWN을 결정해야 한다 (W1, W2의 크기는 대략 수백만개 이상일것이다). 어떤 시점(n)에, 판단이 UP으로 결정이 되었다고 가정해보자. 그리고 별 일이 일어나지 않아서 보상으로 0을 받고 다음 시점(n+1)이 되면 또 100,800개의 값이 (다음 화면이) 입력으로 들어온다. 또 이걸 하고, 이걸 수백번 반복하고 나면 어느순간 드디어 0이 아닌 보상을 받게 될 때가 올 것이다. 예를 들어 우리가 게임을 이겼고 (만세!) 그래서 +1의 보상을 받았다고 하자. 그런데, 그동안 반복한 수백번의 행동중에 어떤 행동이 승리에 결정적인 요인이 되었는지 판단할 수 있나? 마지막에 움직인건가? 아니면 76프레임 전에? 아니면 10프레임과 90프레임때? 그리고 수백만개의 가중치를 어떻게 바꿔야 좋을지 어떻게 구할 수 있나?
이 문제를 credit assignment problem이라고 부른다. 즉, 어떻게 공을 치하해야할지를 할당하는 문제이다. 진짜 결정적인 요인으로 우리가 공을 받아내기 어려운 곳으로 보낸 행동이 있을 것이다. 그리고 그 이후의 움직임은 승리에 전혀 도움이 되지 않는 행동이었다. 이걸 판단하는 문제는 언뜻 생각해도 쉽지 않다.
지도 학습 (Supervised learning)
PG를 하기 전에 잠시 지도 학습에 대해 알아보자 (강화 학습과 지도 학습은 사실 꽤 비슷하다).
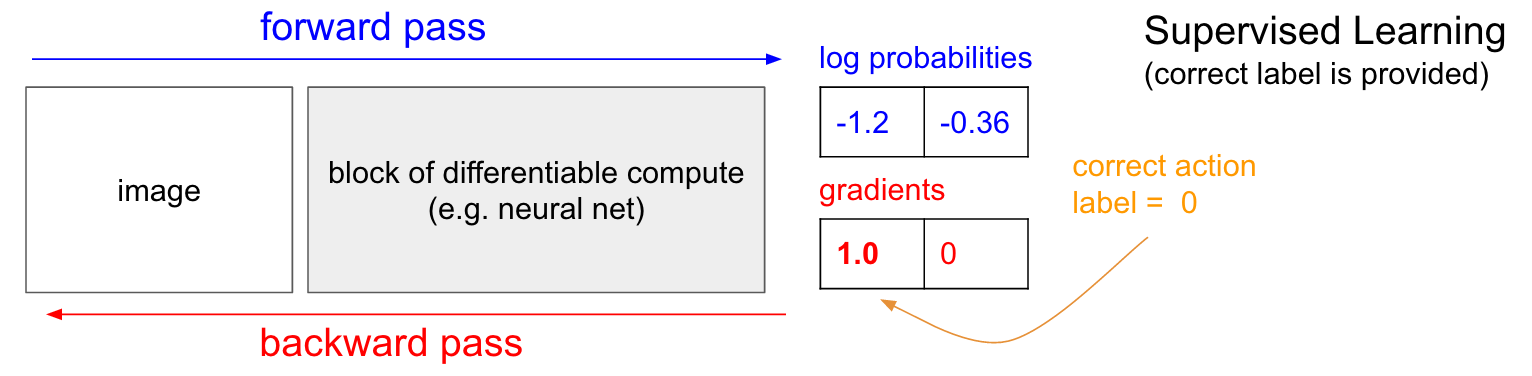
아래 그림은 지도 학습을 나타낸 그림이다. 입력 데이터로 이미지를 넣으면 forward pass를 거쳐서 결과로 각 라벨에 해당할 확률을 구할 수 있다 (여기서도 라벨이 UP/DOWN이라고 가정하자). [0, 1]의 확률이 아닌 log(확률)을 그림에 -1.2와 -0.36으로 표시했다 (30%와 70%에 해당한다). log(확률)로 쓴 이유는 이렇게 log()를 씌우는 것이 여러모로 계산하기에 편하기 때문이다. 로그 함수는 단조 증가 함수 (monotonic)라 log(확률)을 다루나 그냥 확률을 다루나 결과는 같다.
아무튼 forward pass를 통과해서 확률을 구했다고 하자. 그 결과가 UP이라면 UP 라벨의 그라디언트(기울기, 미분)를 1.0으로 놓고 backprop을 통해 각 가중치에 대한 그라디언트 벡터 ∇_W log p(y=UP∣x) 를 구한다. 이 그라디언트는 우리가 갖고있는 수백만개의 파라미터(가중치, 여기에선 W_1과 W_2)를 어떻게 바꿔야(얼만큼 증가 혹은 감소) 현재 입력을 넣었을 때 UP을 출력할 확률을 살짝 증가시킬 수 있는지를 알려준다. 예를 들어 어떤 가중치 값에 대한 그라디언트가 -2.1이라면 (그리고 학습률, Learning rate이 0.001이라면) 그 가중치 w는 w - (-2.1)*0.001 로 업데이트된다. 그리고 이 업데이트 덕분에 다음번에 비슷한 이미지가 들어왔을 때 올바른 판단을 내릴 확률이 살짝 증가한다.
정책 그라디언트 (Policy gradients)
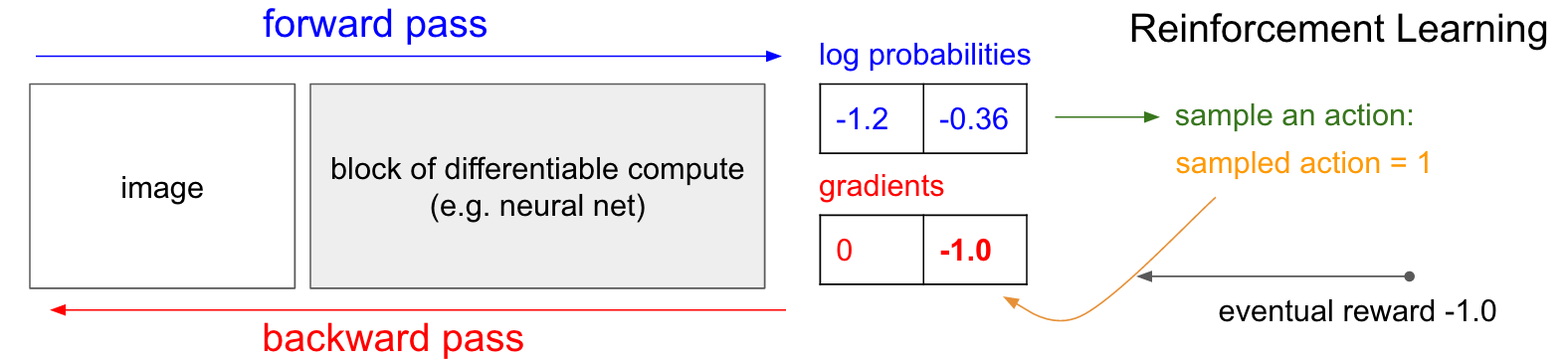
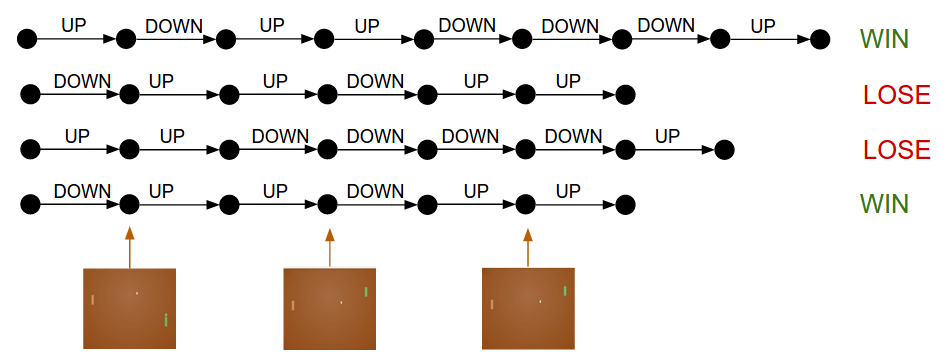
그런데 강화학습이라면, 즉 우리가 정확한 라벨 값을 모른다면 어떻게 될까? 사실 구성은 비슷하다. 이번에도 정책망이 p(UP)=0.3, p(DOWN)=0.7의 값을 계산했다고 하자. 따라서 log(p(UP))과 log(p(DOWN))이 각각 -1.2, -0.36이 나왔다. 그리고 위에서 설명했듯이 이 30%와 70%의 확률 분포에서 샘플링을 하게 된다 (즉, 앞과 뒤가 각각 30%, 70%로 나오도록 설정된 동전을 튕겨서 결과를 사용한다). 샘플링의 결과가 DOWN이라고 가정하자. 그러면 이제 퐁의 막대기를 아래로 한번 움직이고 게임은 계속 진행된다. 자, 여기에서 지도학습과 차이가 나오게 된다. 이 시점에서 우리는 DOWN이 올바른 선택인지, 잘못된 선택인지 아직 알 수가 없다. 하지만 걱정할 필요 없다. 그냥 시간을 두고 기다리면 된다. 예를들어 퐁 게임이라면 게임이 끝날때까지 기다리면 된다. 게임이 승리로 끝나면 +1의 보상을, 패배로 끝나면 -1의 보상을 받게 된다. 그리고 이 보상 값을 DOWN의 그라디언트로 입력한다. 아래 그림을 보면 결과적으로 우리는 게임에서 패배했고 따라서 -1의 보상을 받는다 (eventual reward = -1.0). 이 값을 -log(p(DOWN))에 집어넣고 backpropatagion을 하면 결과적으로 아까의 상황에서 DOWN을 할 확률을 살짝 낮추게 업데이트된다.
이게 바로 강화학습의 원리다. 샘플링에 기반한 정책(stochastic policy)으로 행동을 결정하고, 게임에 승리할 경우 같은 선택을 할 확률을 증가시키고 패배했을 경우 감소시킨다. 보상은 꼭 -1과 1일 필요는 없다. 예를 들어 게임의 결과가 엄청 좋다면 +10을 줄 수도 있다. 파라미터 업데이트는 인공 신경망이 알아서 해줄 것이다.
학습 과정
학습 과정을 자세히 살펴보자. 우선 W1, W2는 임의의 값으로 초기화된다. 그리고 퐁 게임을 100번을 시키자 (이를 rollouts이라고 부른다). 게임 한판마다 200개의 프레임으로 이루어져있다고 가정하면 UP/DOWN의 선택을 총 20,000번 하게 된다. 그리고 2만번의 선택에 대해 우리는 승/패에 따른 보상을 입력하고, 결과적으로 2만번의 선택에 대해 가중치를 어떻게 업데이트해야할지를 (즉, 각 가중치에 대한 gradient를) 알고있다. 예를 들어 아직 학습이 많이 이루어지지 않아서 12번을 이기고 88번을 졌다고 하자. 그러면 승리한 12번 게임에서 이루어진 판단, 즉 12*200=2400번의 판단은 올바른 판단으로 보게 되고 따라서 앞으로 같은 판단을 내릴 확률을 조금씩 증가시킨다. 그리고 88*200=17,600의 판단을 잘못된 판단으로 보고 앞으로 같은 판단을 내릴 확률을 조금씩 감소시킨다. 이렇게 하면 정책망이 전보다 조금 더 올바른 판단을 내리게 된다.
이 과정을 계속 반복하면서 정책망을 학습시킨다.
이 과정을 곰곰이 생각해보면 조금 불완전하다. 예를 들어 어떤 게임에서, 프레임 50에서 올바른 판단을 내렸지만 프레임 150에서 잘못된 판단을 내려서 최종적으로 게임에서 패배했다면, 프레임 50의 올바른 판단마저 부정적인 피드백을 받게 된다. 그렇지만 게임을 수백, 수천번 반복하면서 최종적으로는 올바른 판단은 +보상을, 잘못된 판단은 -보상을 받게 되는 것이다.
더 일반적인 advantage functions (보상 함수)
지금까지 설명한 과정에서는 게임에서 모든 행동을 그 게임의 승/패에 직접적으로 연관지어서 업데이트했다. 즉 게임에서 내린 200번의 판단과 그 게임의 승/패를 그대로 연결지었다. 실제로는 이것보다 조금 복잡한 과정이 있다. 상식적으로 생각해보면 모든 판단은 판단을 내린 직후에 가장 영향력이 크고, 시간이 지나면 점점 상관관계가 줄어든다. 즉, 게임이 200프레임에서 끝났다면 199, 198, 197 프레임의 판단은 승패에 큰 영향을 끼친 반면 1,2,3프레임의 판단은 사실 별 상관이 없을 것이다. 이를 고려해서 각 판단의 보상을 계산하는 경우가 많다. 즉 특정 시점 t에 내린 판단의 보상을
R_t=sum_{k=0}^{\inf} \gamma^{k} r_{t+k}, (역자 주: 기호로 나타내면)
Rt=∑_k=0 ^{∞} γ^k r_{t+k}
로 계산하는 것이다. 여기서 γ는 1보다 조금 작은 값(예:0.99)을 사용해 '망각'을 모델링 한다.
실제로 구현하는 경우에 또 하나 고려할 내용은 각 보상을 표준화(standardise)하는것이다. (역자 주: 이 내용은 생략합니다.)
정책 그라디언트 유도하기
(역자 주: 수식을 쓰기가 어렵기도하고 이 내용은 기본적인 소개보다 살짝 더 나간 부분이라 생략합니다.)
학습
이제 정책망에 대해 이해했으니 실제로 구현을 해보자.
퐁 게임을 130줄짜리 파이썬 코드로 짰다. 이 코드는
OpenAI Gym을 사용했다. 200개의 은닉 노드(hidden node)를 갖는 정책망을 짰고 RMSProp으로 학습을 시켰다. 내 구형 맥북으로 3일동안 학습을 시킨 결과 아타리에 내장된 인공지능보다 퐁을 더 잘 플레이하게 시작했다. 학습기간동안 대략 20만판의 퐁을 플레이했고 최종적으로 800번정도 파라미터를 업데이트했다. 전체 네트워크 구성을 더 정밀하게 짜고, GPU를 써서 더 오래 학습을 시킨다면 이것보다 좋은 결과를 볼 수 있을 것이다. 여기에서는 너무 열심히 최적화를 하진 않았다.
학습된 결과
아래 그림은 학습이 끝난 가중치를 시각화한것이다. 위에서 이야기했듯이 (현재 프레임 - 과거 프레임)을 입력으로 사용했다. 아래 그림은 200개 뉴런중 40개를 골랐다. 하얀 픽셀이 양수, 검은 픽셀이 음수다. 이를 보면 몇몇 뉴런은 공의 궤적에 반응하도록 학습이 된것을 알 수 있다. 실제 게임에서 공은 딱 한군데에만 있을 수 있지만 뉴런 하나는 다양한 공의 위치에 반응할 수 있도록 (multi-task) 학습이 되었다. 데이터에 노이즈가 좀 있는데, L2 정규화를 했다면 아마 줄어들었을 것 같다.
학습 과정에서 일어나지 '않는' 것
지금까지, 픽셀 데이터를 보고 퐁 게임을 하는 정책망을 봤고 실제로 잘 작동한다. 이 방식은 guess-and-check, 즉 판단을 우선 내려보고 그 판단이 잘했는지/못했는지를 확인하는 과정의 반복이다. 세부적인 내용엔 차이가 있지만 이 방식이 현재 가장 잘 작동하는 방식이다. 한편으로 신기하기도 하지만 내막을 알고보면 다소 실망스럽기도 하다.
사람이 퐁 게임을 학습하는 과정을 생각해보자. 이 게임을 보여주고 게임 방식에 대해 이렇게 설명할 것이다. "너가 저 막대기를 올리거나 내릴 수 있고, 저 공을 쳐내서 상대방이 못받게 하면 너가 이기는거야." 그리고 게임을 시작할 것이다. 이 과정과 강화 학습엔 몇가지 차이가 있다.
- 우리는 언어를 통해 게임의 룰에 대해 알게되지만 강화학습은 그저 보상 함수가 정해져있고 이를 통해 스스로 게임을 파악해야한다. 만일 아무런 설명도 듣지 못하고 게임을 하게 된다면 강화학습과 같을수도 있다. 어쩌면 그런 상황이라면 강화학습이 사람보다 나을 수도 있다. 또, 만일 화면의 픽셀을 뒤죽박죽으로 섞어 놓아서 뭐가 뭔지 알 수 없게 해놓는다면 사람은 전혀 게임을 이해할 수 없겠지만 정책망 입장에선 데이터일뿐이므로 아무런 차이가 없다.
- 사람은 공이 튀기는 방식과 같은 물리적인 지식이나, 상대 인공지능도 이기려고 플레이 한다는 등의 사전 지식을 가지고 있다. 또 막대기를 조종하는 것도 쉽게 이해한다. 하지만 알고리즘은 전혀 그런 지식 없이 그냥 작동한다. 한편으로 생각하면 대단하기도 하고, 다르게 생각하면 그 과정을 정확히 이해할 수 없어서 답답하기도 하다.
- 정책망은 Brute force 방식이다. 즉, 올바른 판단이 무엇인지 모든 경우의수를 다 조사해보고 결과적으로 답을 알게된다. 하지만 사람은 모든 경우를 보지 않아도 추상화 과정을 통해 게임의 작동 방식을 이해한다. 예를 들어 사람은, 퐁 게임에서 인공지능의 움직임이 그렇게 빠르지 않으므로 공을 빠른 속도로 - 즉 직선 코스로 - 보내는 것이 승리하는 방법이라는걸 이해할 수 있다. 하지만 사람도 어떤 경우엔 이런 생각의 과정 없이 무의식적으로 일을 하기도 한다. 예를 들어 수동 기어 차량을 운전하는 법을 배운다면, 처음엔 기어 변속 과정을 머리로 생각하면서 실행하지만 어느 순간이 되면 거의 자동적으로, 무의식적으로 기어 변속을 한다.
- 정책망은 많은 보상을 받으면서 조금씩 학습하지만 사람은 훨씬 적은 데이터를 가지고도 어떻게 해야 많은 보상을 받는지 이해한다. 예를 들어 차를 운전하는 경우 꼭 벽에 차를 박아보지 않아도 그러면 안된다는걸 알고있다.
하지만 반대의 경우도 굉장히 많다. 즉, 정책망을 사용한 방법이 사람을 쉽게 이기는 경우도 많이 있다. 특히 반응 속도가 굉장히 빨라야 한다거나 아주 까다로운 행동을 취해야 하는 경우에 정책망은 사람보다 훨씬 잘 할 수 있다.
이제 원리를 이해했으니 정책망을 이용한 강화학습의 장단점을 알 수 있다. 아직 인공지능은 사람처럼 복잡하고 추상적인 개념까지 이해하면서 작업을 수행하지는 않는다. 하지만 언젠가는 그런날이 올 것이다.
미분 불가능한 연산을 포함한 인공 신경망
이제 마지막으로 한가지만 더 짚고 넘어가자. 이번에 다룰 이야기는 게임과 무관한 정책망 이야기다. 정책망을 이용하면 미분 불가능한 연산을 포함한 인공 신경망을 사용할 수 있다. 이 방법은
Recurrent Models of Visual Attention 논문에서 처음으로 소개됐다. 이 논문은 RNN으로 이미지에서 어디를 '보아야'(visual attention) 할 것인지를 결정한다. 문제는, 인공 신경망으로 어디를 볼지를 결정하는 과정이 미분 불가능한 연산이라는 점이다. 아래 그림을 보자.
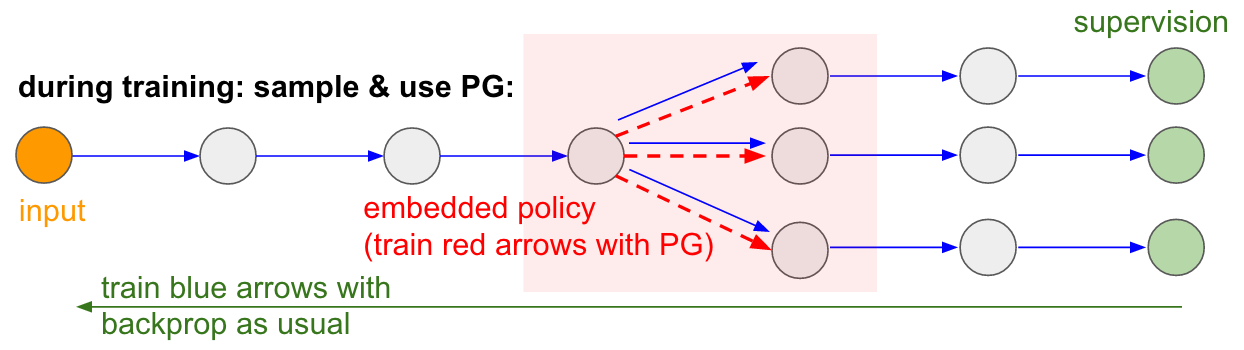
신경망에서 입력이 들어와서 어디를 볼지를 결정하는 과정을 간략히 나타낸 그림이다. 여기에서 대부분의 과정은 미분이 가능하지만 빨간색 화살표로 나타낸, 어디를 볼지를 '확률 분포에 의해 샘플링하는 과정'은 미분이 불가능하다. 따라서 backpropagation을 할 수가 없다.
정책망을 이용하면 이 문제를 해결할 수 있다. 위의 그림에서 샘플링하는 경우의 수를 3가지로 보고 나타내면 아래 그림처럼 된다. 학습 과정에서, 여러번의 샘플링이 일어나게 되고 실제로 샘플링의 결과를 따라서 backpropagation을 하면 된다. 이 과정은
Gradient Estimation Using Stochastic Computation Graphs에 잘 나와있다.
학습 가능한 메모리 입/출력
위의 아이디어는 다른 연구에서도 볼 수 있다. 예를 들어
Neural Turing Machine은 '메모리 테입'이라 불리는 요소가 있고 여기에 데이터를 저장하고 불러온다. 뭔가를 저장하려면 m[i]=x 같은 연산을 수행해야하는데, 여기에서 i와 x는 RNN으로 구현된 컨트롤러 신경망이 결정한다. 이 경우도 샘플링이랑 비슷한데, 예를 들어 i가 아닌 위치를 사용할 경우에 발생하는 loss를 알려줄 방법이 마땅치 않다. 따라서 모든 메모리 셀 - 즉 모든 i - 에 대해 어떤 값을 할당할지를 전부 구해주고, i의 확률 분포를 전부 구해야 하는데 이렇게 하면 하나의 쓰기 연산을 위해 메모리 테입의 모든 위치 (모든 i)를 확인해야 한다. 따라서 연산이 엄청나게 비효율적이다.
정책망을 쓰면 이를 효율적으로 해결할 수 있다 (
RL-NTM 참조). 위의 여러 과정에서 샘플링을 했던 것 처럼, 메모리의 어디에 쓰기 연산을 수행할지 - 즉 변수 i - 를 샘플링하고 그 결과를 지켜보는 것이다. 실제로는, 수많은 메모리 위치 중에서 정확한 위치 i를 샘플링할 확률이 매우 낮기 때문에 이 방식은 경우의 수가 많은 상황에서는 적합하지 않다.
하지만 언젠가 아주 많은 연산과 데이터가 가능해지면 정책망을 통해 이 문제를 해결하게 될 수도 있다. 그리고 이 모든것이 더욱 더 발전하면 TCP/IP이나 컴파일러 등 복잡한 상황을 인공 신경망을 통해 해결하게 될 수도 있을 것이다.
결론
지금까지 정책망을 이용해 게임을 학습하는 방법을 알아봤다. 몇 가지 내용을 덧붙이겠다.
인공 지능의 발전에 대해
여기서는 모든 경우의 수를 다 탐색하는 (brute-force) 방법으로 알고리즘이 작동하는 것을 보았다. 또 사람은 이 경우에 인공지능과 전혀 다르게 접근한다는 사실도 언급했다. 이 과정에서 라벨을 명시하기에 매우 어려운, 따라서 지도 학습을 통해 풀기 어려운 내용이 많이 있기 때문에 비지도학습에 기반한 생성 모델(unsupervised generative model)이 많은 주목을 받고 있다.
복잡한 로보틱스 문제
이 알고리즘은 정말 많은 판단을 내려야 하는 복잡한 상황에 적용되기엔 연산량이 너무 많다. 예를 들어 자동으로 여러가지를 학습하는 로봇의 경우에 샘플링 기반의 학습은 적합하지가 않으므로 나온 방법이
deterministic policy gradients다. 그 외에도
구글의 로봇 팔이나
테슬라의 자동 운전 등의 다른 접근이 있다.
그 외에도 경우의 수를 탐색하는 과정을 최적화 하는 다양한 시도가 있다. 예를 들어
알파고는 무작위 판단이 아니라 사람이 선택한 경우의 수를 기반으로 학습의 효율을 높였다. (역자 주: 이 문단 뒤쪽은 생략합니다)
현실에서 정책망을 사용하는 방법
마지막으로, 내 RNN 포스팅과 비슷하게 마무리를 짓고싶었다. 아무래도 내 RNN 포스팅을 읽은 사람들이 RNN을 이용하면 이 세상의 모든 sequence 데이터와 관련된 문제를 해결할 수 있다고 생각하는 것 같다. 하지만 실제로는 여러가지 까다로운 문제를 해결해야 RNN을 잘 활용할 수 있고, 굳이 RNN을 사용하지 않아도 될 수도 있다.
정책망도 마찬가지다. 이 모든 과정은 완전 자동이 아니고, 데이터가 아주 많이 필요하고, 학습 과정이 엄청나게 오래 걸리고, 잘 작동하지 않는 경우엔 디버깅을 하기가 매우 까다롭다. 정책망을 적용하기 전에 먼저
Cross-entropy method를 베이스라인으로 구현해봐야한다. 그리고 나서도 정책망을 사용하려고 한다면 각종 책과 논문에 나온 나온 팁을 아주 자세히 보고, 아주 간단한 구성부터 시작을 해야한다. 그리고 일반적인 정책망보다는 약간 변형된 방법인
TRPO를 시도해보도록 해라.
대부분의 경우에 더 잘 작동한다고 알려져있다. TRPO의 핵심은 ...(역자 주: 제가 정확히 몰라서 이부분 생략합니다).
자, 이제 포스팅을 마친다. 이 포스팅으로 강화 학습에 대해 잘 이해했길 바란다. 강화 학습 연구에 더 본격적으로 참여하고 싶다면
OpenAI Gym을 활용하길 바란다.

 (1)
(1) (2)
(2)